应用背景如下:
现有不知来路的PDF文件,转成DWG后,原本的数字变成Polyline,本想着通过OCR等途径识别出数字,结果研究了半天,就找到一个插件,然后还不会用,感觉路子有点难,走不下去,然后换了思路。
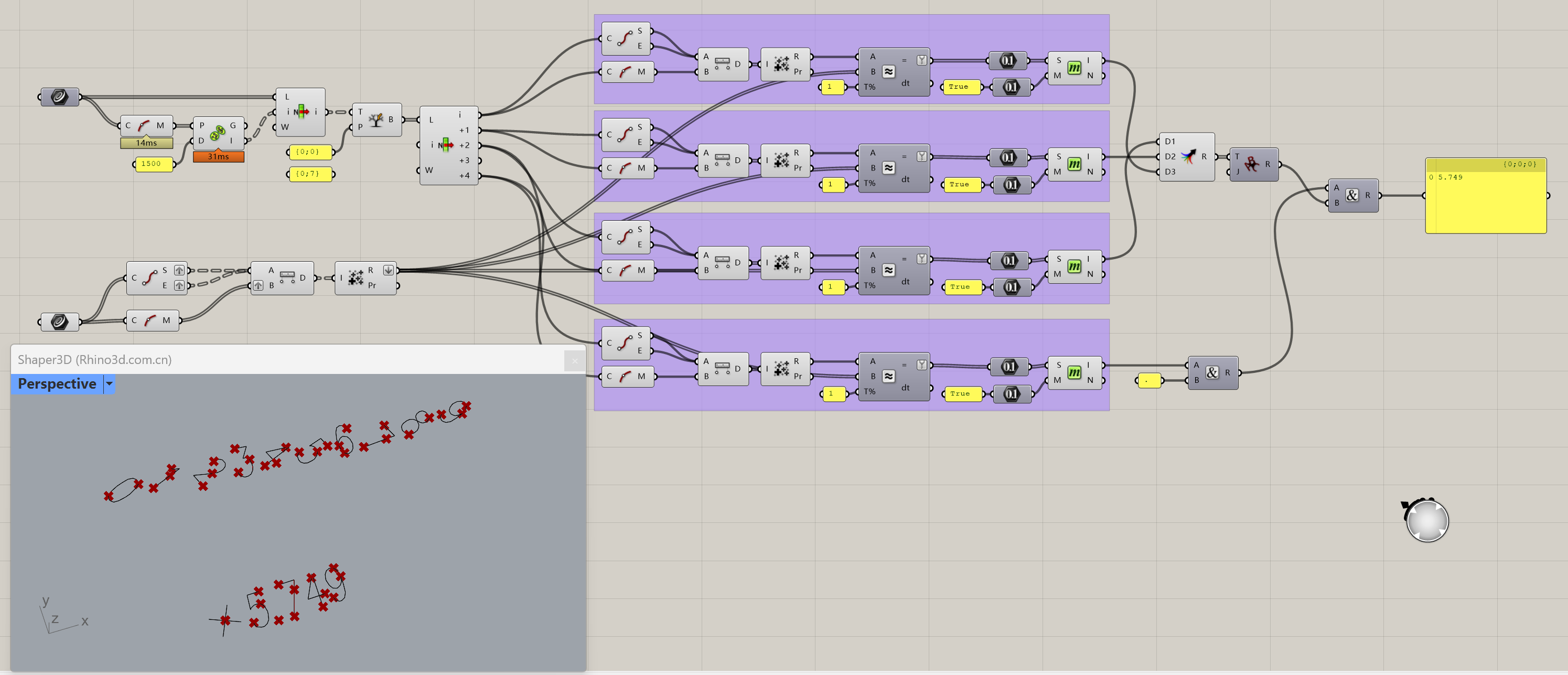
一共十几个PDF文件,发现转完DWG后的Polyline质量还不错,比如同一个数字的线条数量基本一致,曲线长度略有差别,如下图
于是乎就开始各种筛选,过程中又穿插了一些节点,检查源数据中是否有漏网之鱼,最终实现了 想要的结果。
测试文件如下:
PDF转DWG文字识别.gh (222.2 KB)
但毕竟我这种做法过于投机取巧,再换一个来路不明的PDF可能就又歇菜了
所以想请教大佬们,有没有那种正统的将Polyline识别成数字或字母的的思路(比如OCR,还是机器学习之类的,我不怎么懂…)
感谢!
1 个赞
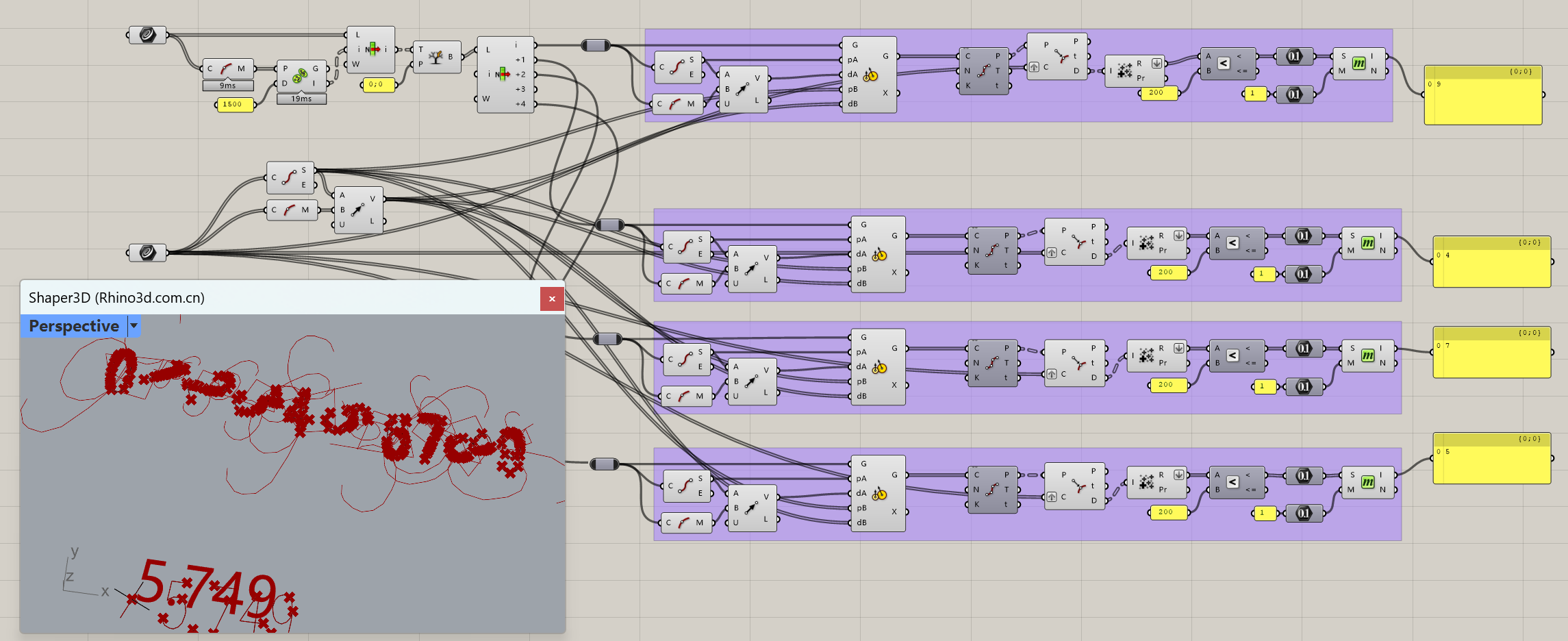
我的思路是,先根据线段的中点之间的距离根据一定数值分成树形数据,分开后的每个树枝代表一个数字,这里以0;0这条树枝为例,观察后发现列表中的第4,3,2,1,0条曲线数据其实就是5.749这个数字.那么接下来就是怎么判断曲线代表的是数字几了,这里我尝试拷贝数字0-9,并对0-9的数字找一些规律,例如从曲线的起点和终点向自己的中点取距离然后相加,那么数字0-9各自的这个相加的数据可以认为是相对固定并有区别的,当把之前的列表中的曲线也这样操作后,进行比较,如果是约等于的结果,就可以认为是代表的相应数字.之后运用memberindex取得数字并进行简单的组合后就的到这个数字了.仅供参考.
1 个赞
早上好J大,
PDF不方便提供 
我已经将Polyline数据内置到gh中
尝试过用pdf转换器将pdf读成dwg,同时也用rhino直接读pdf,结果都是数字直接转换成Polyline
假如抛开pdf不讲,碰到这种形似数字或者字母的曲线,我该怎么把它正确的识别呢,这是我想请教的 
感谢大佬提供思路!
暂且撇开我想请教的OCR识别等不谈。
如果只是通过曲线长度之类的特征值来判断确实简单了一些。开始的时候我也是这么想的,但因为6和9比较特殊,所以初始就舍弃用曲线长度来筛分,就想着用曲线是否闭合,是否自相交将所有曲线大致分成几大类,然后在后面的某些分组中对待曲线长度明显不同的“数字”再通过曲线长度筛分偶尔再掺杂着曲线段数来筛分。
如果接着你这个思路走,整体的流程上应该会简化很多。这个转完的文件质量还不错(源数据处理一大部分之后才发现的),多个pdf文件转完后,同一个“数字”几何属性几乎相同,如果说按照你的“约等于”来快速区分,特殊的“数字”再特殊对待,在完全相信每个“数字”曲线不会突变的情况下,那么整体流程会缩短很多。
再次感谢!
PS:大佬有别的曲线识别思路咩
用长度距离等简单判断确实有点不是很严谨,那么换一个思路,用类似两点对齐的方式把曲线对应到0-9的起点和中点,然后分段后得到的点拉回,距离相加,趋向于0或者说数值最小的那个就是代表的数字。我也新手,树形数据学的不好,还需要梳理一下数据。