
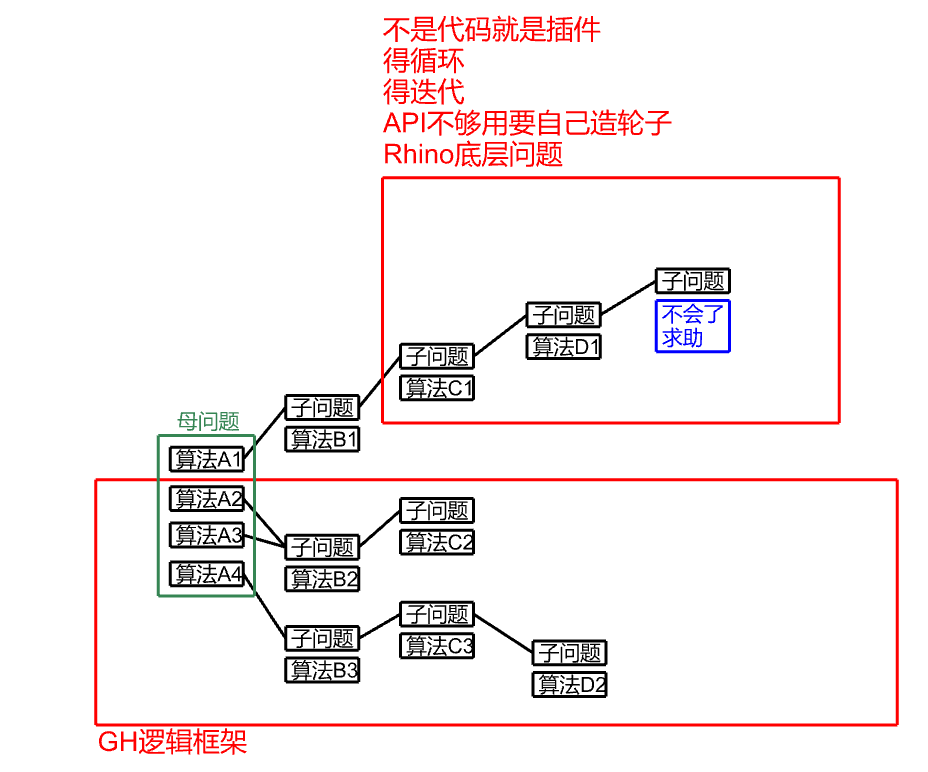
归根结底还是不熟悉GH的逻辑架构
不知道他本质是什么,能做什么,不能做什么,不方便做什么
在这个情况下冷不丁抛出一个已经很靠近末端的子问题
分分钟这个问题就超出了GH自身能解决的范围,又或者能解决但是办法很绕很难说
所以我相信一个熟悉GH架构的人会在一开始看到母问题就选择算法A2 A3 A4
后面就不会出问题了。
当他认为只有算法A1能解决这个母问题时,他会详细评估后续算法B1, C1,D1的难度
来判断自己将来会不会走到死胡同,一直到不得不求助的程度。
你的问题我暂时没想好什么妙招。不过我总感觉有哪里不对。就先发出来了

这个算法确实挺巧妙的,,花了几天才理解消化。  感谢鹿神
感谢鹿神
我觉得你还是看一下我的二楼回帖吧。
就算是能折腾,经常碰到这种问题也折腾不起啊。
年纪大了 
要的,gh做这种循环的是有点局限性,太烧脑~以后学学代码配合用
大部分问题都不需要代码,也不需要循环结构。
效率最高的做法还是GH做到滚瓜烂熟,然后将碰到的问题纳入到GH的体系中。
什么样的工具适合做什么事情。
循环是GH的弱项,但是一定程度的基础技能可以将很多 看似需要循环的问题化解为线性问题。
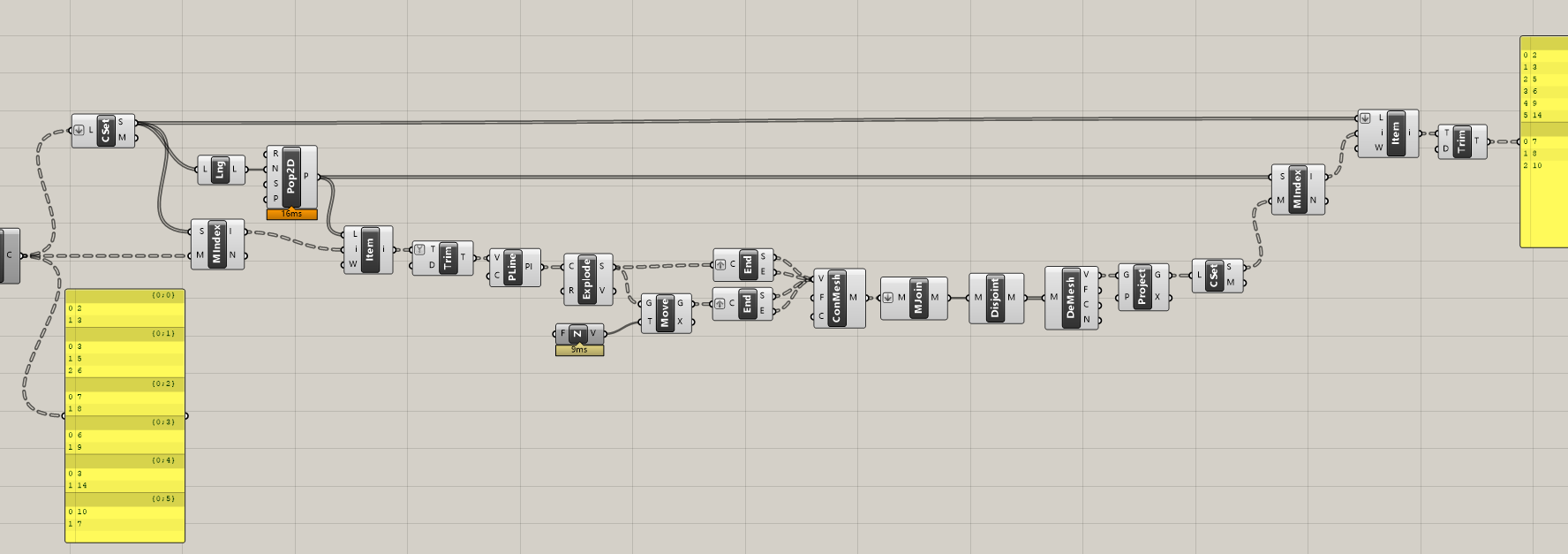
首先给出一个解法(用到了k-means):

核心思路:
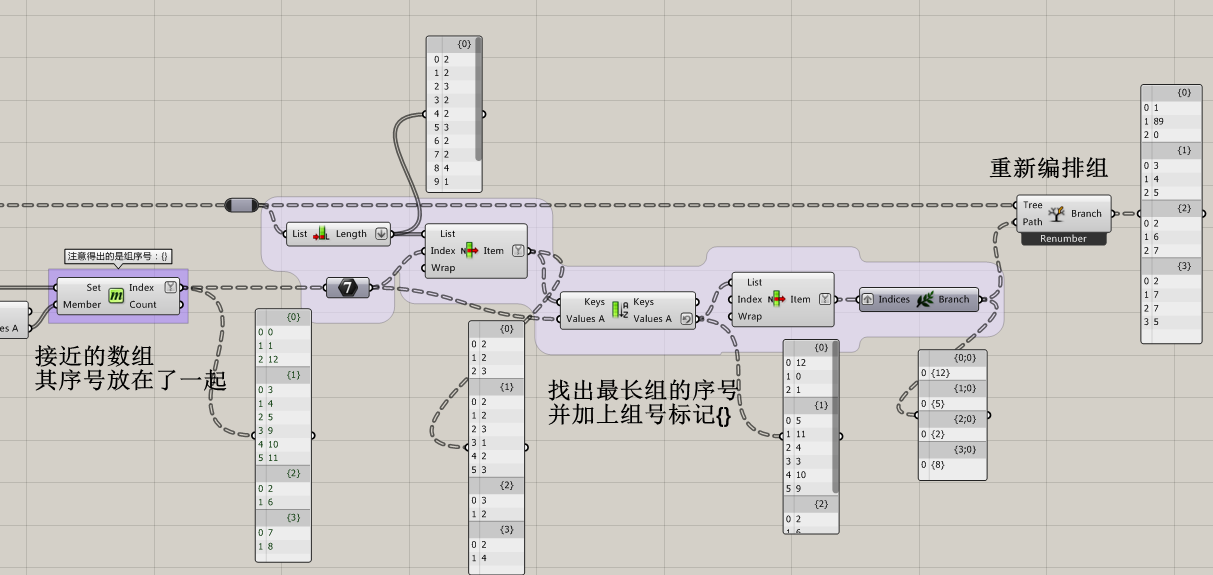
根据每个数字在数组中存在的多寡,把每个数组转成唯一编码,再用聚类分析,看哪些编码比较相近可以归到一起,就可以解出分组序号。再用这些序号重新去取原来的数组,就可以把相近的排列在一起。
这里有个巧合是分组序号恰好为数组内容,所以后续加入了一些奇怪的数组来验证,完善了后续脚本,好像还行。
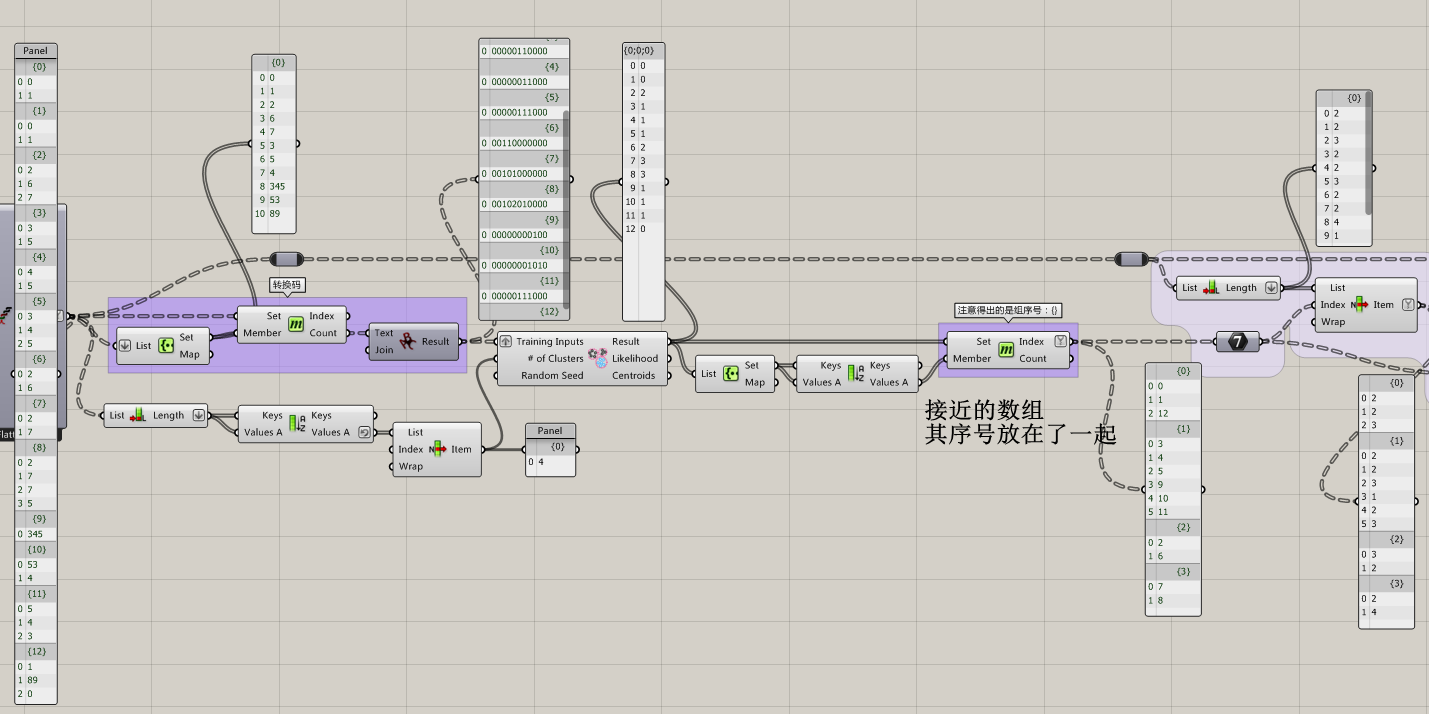
当然,这个脚本的鲁棒性在某些方面可能比较一般,比如无法区分
其实就还蛮尴尬的。
*另一个尴尬的事是我发现# of clusters似乎不该指定分组数量;分组数量等于最长的组内长度似乎完全是个巧合…所以具体分几组最好手拉一下看看,有空再改吧
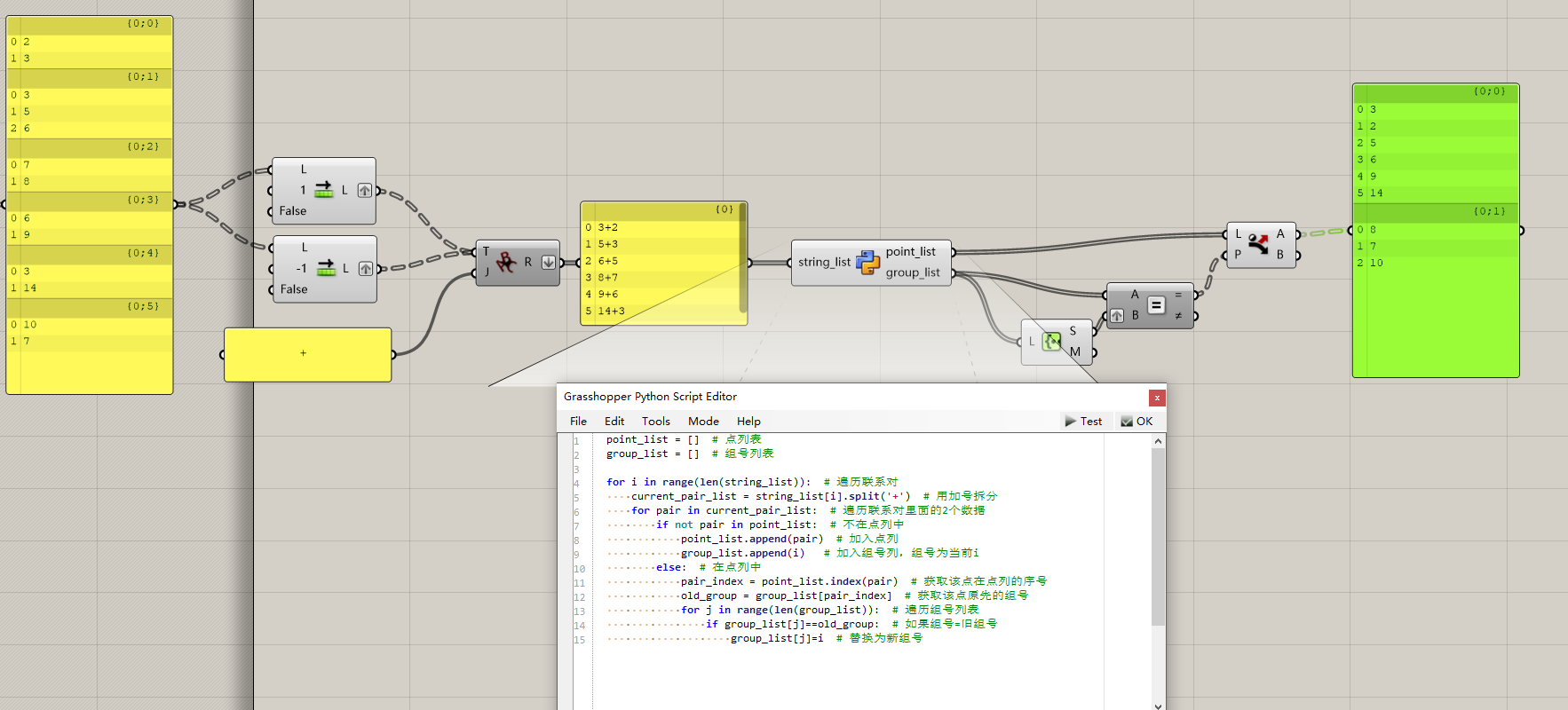
@NARUTO 我实在是折腾不来py还是C#的GH数据结构,只能在代码前后做处理。抛砖引玉一下请月神来帮助完善一下。
GH其实应当增加这样的电池,总说用些什么基本电池和转换成什么几何,折腾来折腾去,是有背GH开发初衷的,多听听用户的
我同意你说的相同元素分组,提供一个自带的电池。
但楼主的问题不是简单的相同元素分组,而是跨组的元素合并。
你可能搞错了问题
多人问过,说明需求多,在论坛学到很多东西,谢谢老师的回应!就是要跨组的数据,有一个数据相同就合并成新组的电池.对会写程序的人,不值一提.对普通用户,真不想多花半年时间学C#,如果有电池大大简化.合并分组,循环本来就是处理数据的基本手段.期待8.0GH2这些都不是问题,现阶段就采用论坛老师们的方法和用插件吧.
我再明确一下
本贴这个问题【就是要跨组的数据,有一个数据相同就合并成新组的电池】有一定难度,并不属于“会写程序的人不值一提”的范畴。
碰到这类问题首先考虑更换思路。
GH 2.0并不会增加这样的需求,因为他太特殊。
也不存在 【多人说过】
就我个人来看,并没有发现【需求多】
需求多并且多人说过的,并且GH将来可能会增加的,是例如[1,1,1,2,2] = [1,1,1],[2,2]的简单分组
最后针对这个问题给出建议:
如果你真的发现自己的电池非要操作这样的跨分组合并不可了,
说明思路很早很早就走偏了。
并不是“我应当有能力解决这个问题”或者“这个软件应该给我提供这个功能”
而是“我自己不小心把问题想偏了,导致问题复杂化”
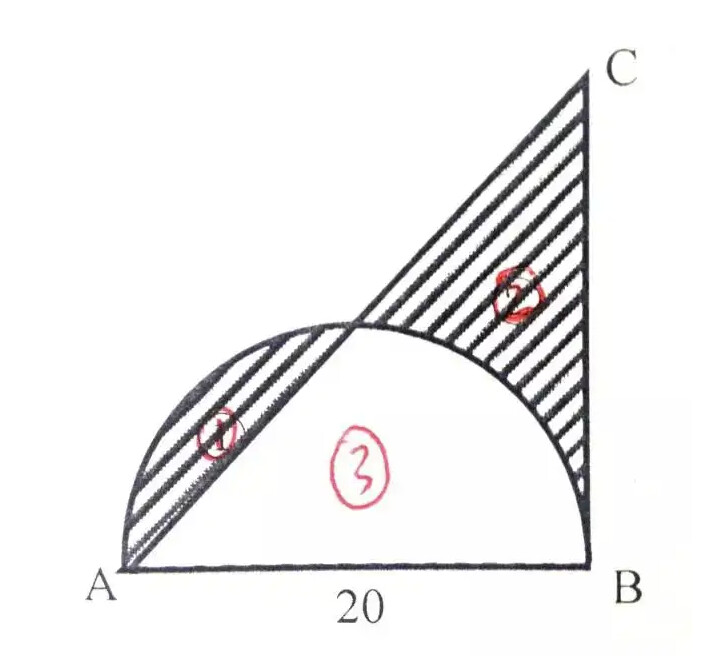
求阴影部分面积,半径=1
你可能会觉得他会用上圆的面积公式,那就是初中数学
但这是小学数学的习题,阴影部分面积=1
当你思路并不正确时,会抱怨我还不会求圆的面积,这题没法做,这对初中生来说不值一提。诸如此类